들어가며
-
David Lamkins의 Successful Lisp한국어 번역본입니다.- 번역을 허락해주셔서 감사합니다
David Lamkins. - 그의 웹사이트는 http://lamkins.net, github는 https://github.com/TieDyedDevil입니다.
- 그의 책은 아마존 닷컴 이곳에서 원서로 구입할 수 있으며 온라인 버전은 이곳에서 볼 수 있습니다.
Successful Lisp의 모든 저작권은 David Lamkins에게 있습니다.
- 번역을 허락해주셔서 감사합니다
-
This is Korean translation version of
David Lamkins's Successful Lisp.David Lamkins, Thank you for allowing me to translate your book.- His personnal website is http://lamkins.net, github is https://github.com/TieDyedDevil.
- You can buy His original book on Amazon.com here and you can check his online version of successfull lisp here.
David Lamkins owns All of Successful Lisp's copyright.
03장. 12개의 레슨으로 배우는 필수 리스프
이번 장은 여러분에게 리스프를 시작하기에 앞서 알아야 할 모든것을 가르칠 것입니다.
언어의 코어 기능들을 모두 다룰 것입니다. 여러분이 이 코어를 리스프 자체라 생각하고, 그렇지 않은 것은 하나의 거대한 표준 라이브러리라 생각하셨으면 합니다. 책을 읽은 후 이를 배경으로, Common Lisp : The Language, 2nd Edition과 같은 메뉴얼을 참조하면, 더욱 편하게 리스프의 남은 부분들을 배울 수 있을 것입니다.
여러분은 이번 장을 한번에 쭉 읽어야 합니다. 이따금 다음 단락이나 다음 장에대해 언급하겠지만, 이번장을 이해하기 위해서 반드시 그러한 참고들을 따를 필요는 없습니다. 이번 장을 끝낼 무렵, 여러분은 이미 리스프 시스템의 키보드 앞에 앉아 4장을 진행하고 있을 것 입니다.
짚고 넘어가기
레슨 01. 필수 - 신택스(Essential Syntax)
리스트는 괄호로 감싸져있다
리스프에 대해 우선적으로 알아할 것입니다: 괄호로 둘러싸인 모든것은 리스트(list)이다.
여기 예가 있습니다:
(1 2 3 4 5)
(a b c)
(cat 77 dog 89)
앞서 말씀드린대로, 괄호로 둘러싸인 것은 리스트입니다.
이와 같은 말을 들으면, 아마 다음과 같은 의문이 생길 것입니다:
- 괄호로 아무것도 없는것을 둘러싼다면?
- 괄호로 다른 리스트를 둘러싼다면?
두 경우 모두 대답은 같습니다. 여전히 리스트입니다.
따라서 다음 나오는 것들 또한 리스트입니다:
()
(())
((()))
((a b c))
((1 2) 3 4)
(mouse (monitor 512 342) (keyboard US))
(defun factorial (x) (if (eql x 0) 1 (* x (factorial (- x 1)))))
리스트가 아닌 유일한 경우는 다음 4개의 예제에 나온 것처럼, 좌/우측 괄호가 짝을 이루지 못하는 경우입니다:
(a b c( ; (: 2개 // ): 0개
((25 g) 34 ; (: 2개 // ): 1개
((()) ; (: 3개 // ): 2개
(())) ; (: 2개 // ): 3개
크게 신경쓸 부분은 아닙니다: 리스프는 괄호가 일치하지 않으면 않다고 여러분에게 알려 줄 것입니다. 또, 리스프 프로그램을 작성하기 위해 사용하는 편집기 대부분은 자동적으로 일치하는 괄호를 찾는 방법을 제공해 줄 것입니다. 27장에서 편집기에 대해 살펴볼 수 있습니다 [p 227].
리스프에서 리스트는 여러가지가 될 수 있습니다. 가장 일반적인 경우, 리스트는 프로그램이나 데이터가 될 수 있습니다. 그리고 리스트가 스스로 다른 리스트를 만들 수 있기에, 여러분은 복잡한 데이터의 조합과 여러 단계의 리스트 구조로 된 프로그램을 가질 수 있습니다. 이를 잘 이해하는 자에게는 리스프는 엄청난 유연성을 부여해 줄 것이며, 그렇지 않은 자에게는 많은 혼란을 줄 것입니다. 이번장을 계속해서 나아가면서 이러한 혼란을 없애도록 노력해 봅시다.
아톰(Atom)은 공백이나 괄호로 분리된 것이다
이제 여러분은 리스트를 구분할 수 있으며, 괄호 사이에 나타나지만 (리스트가 아닌)단어나 숫자인 것들에 대한 것들을 뭐라고 부르는지 알고 싶을 것입니다. 이러한 것들을 아톰(atom)이라 부릅니다.
그러므로, 다음 단어와 숫자들은 모두 아톰입니다:
1
25
342
mouse
factorial
x
리스프에서는 거의 모든 문자를 이용하여 아톰을 구성할 수 있습니다. 이제부터 문자, 숫자, 구두점 문자들이 있는데 이들 앞뒤에 공백(줄의 시작 또는 끝 포함) 또는 괄호가 있으면 이를 모두 아톰이라고 부르겠습니다. 다음 나오는 것들은 모두 아톰입니다:
-
*
@comport
funny%stuff
9^
case-2
만일 다른 프로그래밍에 대한 경험이 있다면, 한가지 주의해야 할 점은 보통 다른 언어에서 연산자로 예약된 문자들이 리스프에서 아톰으로써 쓰였다면 별다른 의미를 갖지 않는다는 것입니다. 예를들어, case-2는 수학적(arithmetic) 표현식 뺄샘이 들어간게 아니라 여기서는 그져 아톰 그 자체입니다.
공백이나 괄호로 무엇이 아톰인지 구분할 수 있으므로, 아톰과 괄호 혹은 괄호들 사이에 있는 공백을 없앨 수 있습니다. 그러므로, 다음 두 예제는 동일합니다:
(defun factorial (x) (if (eql x 0) 1 (* x (factorial (- x 1)))))
(defun factorial(x)(if(eql x 0)1(* x(factorial(- x 1)))))
사실, 여러분은 절대로 두번째에 나타난것처럼 리스트를 작성해서는 안됩니다. 여러분은 가독성을 향상시키기 위해 리스트를 여러 라인으로 분리시키며 각 라인을 적절히 들여써야 합니다. 이 리스트는 사실 작은 프로그램이며, 다음과 같이 들여쓰면 리스퍼 프로그래머가 읽기 수월해 집니다:
(defun factorial (x)
(if (eql x 0)
1
(* x (factorial (- x 1)))))
지금, 여러분은 이것이 무얼 의미하는지, 이러한 종류의 들여쓰기(indentation)가 무엇인지 대해 걱정할 필요가 없습니다. 이번장을 통해, 여러분은 들여쓰기가 들어간 많은 예제를 접하게 될 것입니다.
계속해서 보여드리는 예제와 함께, 가독성을 향상시키는 들여쓰는 방법에 대해 알려드릴 것입니다. 28장 [p 230]에서 적절한 들여쓰는 법을 포함하여, 리스프의 코딩 스타일에 대해 다룰 것입니다.
짚고 넘어가기
- 리스트(list)
- 아톰(atom)
레슨 02. 필수 - 평가(Essential Evaluation)
폼(form)은 평가될 수 있다
폼(form)은 아톰(atom) 혹은 리스트(list)가 될 수 있습니다. 중요한 것은 폼이 평가(evaluation)된다는 것입니다. 평가라는 것은 상당한 기술적 의미를 지니고 있으며, 이번 섹션에서 서서히 그 모습을 드러나게 될 것입니다.
폼이 아톰이라면 평가는 단순합니다. 리스프는 아톰을 마치 이름처럼 다루고, 값이 존재한다면 이름에 저장된 값을 얻습니다. 여러분은 아마도 왜 제가 아톰은 변수라고 직접적으로 말하지 않는지 의아할 것입니다. 명확하게 정의하지 않은 이유는 아톰은 변수이거나 상수의 값을 가질 수 있기 때문입니다. 그리고 아톰의 값은 경우에 따라 상수가 될 수 도 있습니다.
숫자는 아톰입니다(이 값은 상수입니다). 리스프는 숫자에 값을 저장 할 수 없습니다: 숫자는 자체적으로 평가됩니다.
정의가 완전히 내려지지 않은 새로운 용어를 소개합니다. 이제, 심볼을 값을 가질 수 있는 아톰이라고 여기기 바랍니다. 레슨 5[p 53]에서 심볼에 대해 더욱 자세히 살펴볼 것입니다.
defconstant로 정의된 심볼은 상수 값을 지닙니다. 리스프는 변수처럼 아톰에 값을 저장한 다음, 값을 바꿀 수 없다라는 메모를 추가합니다.
패키지에 있는 키워드(keyword) 심볼은 스스로 평가됩니다. 패키지에 관한 것은 31장[p 247]에서 자세히 살펴볼 것입니다. 지금, 여러분이 알아야 할것은 (패키지 프리픽스라 불리는) : 문자로 시작하는 심볼은 키워드 심볼이라는 것입니다. 키워드 심볼은 그 자신을 값으로 갖습니다.
다양한 방식으로 심볼에서 값을 얻을 수 있습니다. 리스프는 실제로 심볼에 다양한 값을 저장합니다. 하나는 변수로서의 심볼의 값. 그리고 다른 하나는 함수로서 심볼입니다. 또 다른 것들은 해당 심볼에 대한 문서를 얻거나, 출력값으로 활용하거나, 연관리스트(associated list)처럼 속성값으로 쓰이기도 합니다. 이러한 것들에 대해 레슨 5 [p 53], 레슨 6 [p 56], 레슨 7 [p 59]에서 더욱 자세히 살펴볼 것입니다.
폼이 리스트라면, 첫번째 요소는 심볼이거나 람다(lambda)표현식이라 불리는 특별한 폼일 것입니다. (람다 표현식에 대한것은 잠시 뒤로 미루겠습니다.)
심볼은 함수의 이름을 짓습니다. 리스프에서 심볼 +, -, *, /는 일반적인 산술 연산자입니다: 덧셈, 빨셈, 곱셈, 나누기. 각 심볼은 산술 연산을 수행하는 함수와 연관되어있습니다.
따라서 리스프가 폼 (+ 2 3)을 평가하면, 이는 덧셈 함수+에 인자 2와 3을 적용시킬 것이며, 예상되듯이 결과 5를 반환할 것입니다. 함수로서 심볼 +가 인자들 앞에 있습니다. 이는 전위 표기법(prefix notation)입니다. 리스프가 리스트를 폼으로 평가하기 위해 무얼할 것인지 이해하기 위해선, 리스트의 첫번째 요소를 살펴보시기 바랍니다.
함수는 인자를 받을 수 있다
주어진 리스트를 평가할때 리스프는 폼을 함수 호출로써 다룹니다. 지금부터 우리는 수 많은 리스프의 평가를 보게 될 것이며, 리스프의 입력과 이의 반응을 구분하기 위해 다음과 같이 시각적 표시를 할 것입니다:
(어떠한 리스프 입력)
;;=> 리스프 평가의 결과
;;>> 리스프 출력
;;<< 리스프에 입력
;;>| 리스프의 에러 메시지
예:
(+ 4 9)
;;=> 13
(- 5 7)
;;=> -2
(* 3 9)
;;=> 27
(/ 15.0 2)
;;=> 7.5
위 경우에서 보듯이, 평가된 폼은 리스트입니다. 각각의 첫번째 요소는 심볼이자 함수의 이름입니다. 남아있는 요소는 해당 함수의 인자입니다. 여기서, 인자는 모두 숫자이며, 숫자는 스스로 평가된다는 것을 알 수 있습니다.
여기 몇몇 예제가 더 있습니다:
(atom 123)
;;=> T
(numberp 123)
;;=> T
(atom :foo)
;;=> T
(numberp :foo)
;;=> NIL
atom과 numberp는 술어(predicate)입니다. 술어는 참 혹은 거짓을 반환합니다. 리스프에서 NIL은 거짓을 나타냅니다. NIL이 아닌 것은 모두 참입니다. 딱히 의미있는 값이 아니면 술어는 관습적으로 참을 의미하는 T를 반환하게 되어 있습니다. atom은 인자가 리스프의 아톰이라면 T를 반환합니다. numberp는 인자가 숫자이면 T를 반환합니다.
위의 폼들을 평가하기 위해, 리스프는 우선 (좌측에서 우측으로) 인자를 평가하고, 그런 다음 첫번째 요소를 평가하여 함수를 얻은 후, 앞선 인자들을 함수에 적용합니다. 몇몇 예외가 있지만, 그것들은 이번 레슨의 끝부분에서 배울 것입니다.
리스프는 리스트 폼을 평가하기 위해 다음과 같은 작업을 수행합니다:
- 나머지 요소들을 좌측에서부터 우측으로 인자들을 평가한다.
- 첫번째 요소에서 함수를 얻는다.
- 함수에 인자들을 적용한다.
아톰 또한 리스프의 폼이라는 것을 명심하시기 바랍니다. 주어진 아톰이 평가되면, 리스프는 아톰이 지닌 값을 반환합니다:
17.95
;;=> 17.95
:A-KEYWORD
;;=> :A-KEYWORD
*FEATURES*
;;=> (:ANSI-CL :CLOS :COMMON-LISP)
"Hello, world!"
;;=> "Hello, world!"
WHAT-IS-THIS?
;;>| Error: Unbound variable
숫자와 키워드는 스스로 평가됩니다. 문자열도 그러합니다. *FEATURES*는 리스프에 의해 미리 정의된 변수입니다. 여러분의 시스템은 아마도 다른 값을 반환할 것입니다.
심볼 WHAT-IS-THIS?는 리스프에 의해 미리 정의되지 않아 값을 지니지 않으며, 이에 값을 얻을 수 없습니다. 시스템은 값 대신에 에러메시지로 응답할 것입니다. 에러 메시지 앞에 ;;>|를 붙여 표시하였습니다. 시스템에 따라 다른 에러 메시지가 출력될 수 있습니다.
함수는 다수의 값을 반환 할 수 있다
우리는 종종 다수의 값을 반환하는 함수를 갖길 원합니다. 예를들어, 데이터베이스 전체를 살펴보는 함수는 요구하는 값과 완료상태코드를 동시에 반환해야 합니다. 이를 행할 방법으로는 해당 결과값을 저장할 위치 자체를 함수에 전달하는 것입니다; 가능은 하지만, 리스프 프로그램에서는 매우 드믄 일입니다.
또 다른 접근법은 결과와 상태코드를 하나로 묶어 하나의 반환 값으로 만드는 것입니다. 리스프는 구조체[p 72]를 포함하여 여러분에게 이를 수행할 다양한 방식을 제공합니다. 다만, 이와같이 하나로 묶는 방식은 잘못하면 가비지(29장 [p 238] 참조)가 생성되어 프로그램 작동 속도가 느려지게 만들 수 있기에 숙련된 리스프 프로그래머는 이와 같은 작업을 피합니다.
함수에서 다수의 값을 반환하는 올바른 법은 values 폼을 이용하는 것입니다. 잠시 후에 함수 컨텍스트안에서의 VALUES의 사용법을 [p 63]에서 살펴보도록 하겠습니다. 지금은, 리스프가 values 폼을 평가할때 무슨 일이 벌어지는지 살펴봅시다:
(values 1 2 3 :hi "Hello")
;;=> 1
;;=> 2
;;=> 3
;;=> :HI
;;=> "Hello"
리스프가 values 폼으로 각 인자에 대한 값을 반환하는 것을 확인할 수 있습니다.
함수 안에서 인자를 수정하지 않는다
앞서, 결과값을 저장할 위치 자체를 인자로 함수에 넘길 수 있으며, 함수가 그 위치의 값을 바꿀 수도 있다고 말한 바가 있습니다. 다른 언어들은 이를 일반적인 레파토리로 말할지라도, 리스프 프로그램에서 매우 드문 일입니다.
저장할 위치에 키워드가 아닌 심볼이나 구조체 같은 것을 넣을 수 는 있습니다. 심볼을 넣을 경우, 함수는 심볼에 새로운 값을 넣는 코드를 수행해야만 합니다. 구조체를 넣을 경우 구조체의 각 값을 올바르게 변경하는 코드를 수행해야만 합니다. 이러한 작업 자체도 복잡하고 이렇게 작성된 프로그램을 이해하는 것도 어렵습니다. 따라서 리스프 프로그래머들은 일반적으로 인자를 수정하지 않고, 인자는 인자, 결과는 결과로 구분된 함수를 작성합니다.
인자는 (보통은) 함수가 적용 전에 평가된다
리스프가 함수를 평가하면, 앞서 봤던것처럼[p 42], 항상 모든 인자를 우선적으로 평가합니다. 불행히도, 모든 규칙에는 예외가 있으며, (곧 보게될 것처럼)이 규칙도 예외는 아닙니다... 문제는 리스프가 함수의 인자를 평가하지 않을 수 있다라는 점이 아니라, 리스트 폼은 함수 호출이 아닐 수 도 있다라는 점입니다.
인자들은 좌측에서 우측으로 순서대로 평가된다
리스트 폼이 함수를 호출하면, 이의 인자는 항상 좌측에서 우측으로 순서대로 평가됩니다.
스페셜 폼과 매크로는 인자의 평가하는 방법을 바꿀 수 있다
리스트 폼이 함수 호출이 아닐 수 도 있다 라고 했는데, 그럼 무엇이 될 수 있을까요? 2가지 경우가 있지만, 결과는 같습니다: 몇몇 인자는 평가되며 몇몇은 평가가 안됩니다. 폼이나 폼이 아니냐에 달려있습니다. 이 예외에 대해서만 알면 됩니다. 다행히도, 대부분의 리스프 시스템은 한두번의 키 입력으로 이에 대한 온라인 문서를 여러분에게 보여줄 것입니다.
모든 인자가 평가되지 않는 폼은 두가지가 있습니다: 스페셜 폼과 매크로. 리스프는 몇몇 스페셜 폼을 미리 정의해 두었습니다. 언어 자체의 주요 기능이기에 여러분만의 스페셜 폼을 추가할 수는 없습니다. 또 리스프는 몇몇 매크로를 미리 정의해두었습니다. 단, 매크로는 저희가 작성할 수 있습니다. 리스프의 매크로를 이용하면 언어의 강력한 힘을 이용하여 우리만의 기능을 추가 할 수 있습니다. 이 장의 뒷 부분에서 간략하게 간단한 매크로를 작성해 볼 것입니다 [p 61]. 20장에서는[p 188] 복잡한 매크로에 대해 다뤄볼 것입니다.
짚고 넘어가기
- 폼(form)
- 키워드(
:) - 전위 표기법(prefix notation)
atomnumberpNILTvalues
레슨 03. 스페셜 폼과 매크로에 대한 예제
이제 스페셜 폼과 매크로에 대해 살펴보도록 하겠습니다. 다음 4개의 레슨들을 거쳐, 가장 기본적인 리스프 데이터 형식, 리스트를 이용하여 간단한 함수를 작성케 해주는 레파토리를 구축할 것입니다. 나머지 장에서는 더욱 복잡한 프로그램 구조와 데이터형식을 다룰 것입니다.
SETQ
이전에, 여러분께 리스프가 심볼 폼을 평가하여 변수의 값을 받온다고 말했습니다. setq는 이 변수의 값을 설정하는 방법을 제공합니다:
(setq my-name "David")
;;=> "David"
my-name
;;=> "David"
(setq a-variable 57)
;;=> 57
a-variable
;;=> 57
(setq a-variable :a-keyword)
;;=> :A-KEYWORD
setq의 첫번째 인자는 심볼입니다. 이는 평가되지 않습니다. 두번째 인자는 변수의 값으로 할당됩니다. setq는 마지막 인자의 값을 반환합니다.
setq는 심볼 그 자체를 값으로 할당하고자 하기에 첫번째 인자를 평가하지 않습니다. 만일 setq가 첫번째 인자를 평가한다면, (할당될 심볼이 있어야 하기에)해당 인자의 값은 심볼이여야 합니다. set 폼이 그러한 일을 합니다:
(setq var-1 'var-2)
;;=> VAR-2
var-1
;;=> VAR-2
var-2
;;>| Error: Unbound variable
(set var-1 99)
;;=> 99
var-1
;;=> VAR-2
VAR-2
;;=> 99
첫번째 폼에서 '을 발견하셨나요? 이것은 다음 폼 var-2 가 평가되는 것을 방지합니다. 이번 레슨 후반에, quote[p 50]를 살펴볼때, 더욱 자세히 설명하도록 하겠습니다.
이번 예제에서는, 우선 var-1의 값을 심볼 var-2로 설정하였습니다. 그 후 var-2의 값을 확인하였고, 아무런 값도 가지지 않았다는 것을 확인하였습니다. 다음으로, (setq가 아닌) set을 이용하여 var-1의 값인 심볼 var-2에 값 99를 할당하였습니다.
사실 setq 폼은 심볼과 값을 번갈아 사용하여 짝수개의 인자를 취할 수 있습니다:
(setq month "June"
day 8
year 1954)
;;=> 1954
month
;;=> "June"
day
;;=> 8
year
;;=> 1954
setq는 좌측에서 우측으로 할당을 수행하고, 맨 우측에 있는 값을 반환합니다.
LET
let 폼은 이전에 봐왔던 것보다 좀 더 복잡해 보입니다. let폼은 중첩된 리스트를 이용하지만, 스페셜 폼은 아니기에 특정 요소만 평가됩니다:
(let ((a 3)
(b 4)
(c 5))
(* (+ a b) c))
;;=> 35
a
;;>| Error: Unbound variable
b
;;>| Error: Unbound variable
c
;;>| Error: Unbound variable
위에 있는 let 폼은 심볼 a, b, c의 값을 정의 후, 이를 이용하여 산술 계산을 하였습니다. 또한 이 계산의 결과가 바로 let 폼의 결과입니다. let에서 정의된 변수가 폼을 평가한 후에는 어떠한 값도 지니지 않는다는 점을 주목하시기 바랍니다.
대게, let은 다음과 같이 생겼습니다:
(let (bindings)
forms)
bindings에는 임의의 수의 두개의 원소를 지닌 리스트가 있으며 (각 리스트는 심볼과 값을 지닙니다), forms에는 임의의 수의 리스프 폼이 있습니다. forms의 평가를 위해, bindings에 의해 수립된 값을 이용합니다. let은 마지막 폼에 의해 반환된 값(들)을 반환합니다.
들여쓰기는 let의 동작에 영향을 미치진 않지만, 적절한 들여쓰기는 가독성을 향상시킵니다. 다음 두 동일한 폼을 살펴보시기 바랍니다:
(let ((p 52.8)
(q 35.9)
(r (f 12.07)))
(g 18.3)
(f p)
(f q)
(g r t))
(let ((p 52.8) (q 35.9) (r (f 12.07))) (g 18.3) (f p) (f q) (g r t))
첫번째 경우, 들여쓰기로 어떤게 바인딩이며 어떤게 폼인지 명확하게 나타납니다. 독자가 let 폼의 두 부분에서 수행된 서로 다른 규칙에 대해 자세히 알지 못할지라도, 들여쓰기는 차이를 나타냅니다.
두번째경우, 여러분은 어디에서 바인딩이 끝나며 폼이 시작되는지 알고자 한다면, 괄호를 세어야만 할 것입니다. 더욱 안좋은 것은, 들여쓰기의 부제는 let 폼의 두 부분에 의해 수행되는 역활의 차이점에 대해 시각적 단서(visual cues)를 없애버립니다.
setq를 이용하여 변수를 정의하고 let 폼에서 동일한 변수 이름을 사용한다면, let을 평가하는 동안 let에 의해 정의된 값이 (setq에 의해 정의된)다른 값을 대체할 것입니다:
(setq a 89)
;;=> 89
a
;;=> 89
(let ((a 3))
(+ a 2))
;;=> 5
a
;;=> 89
좌에서 우로 순서대로 값의 할당이 이루어지는 setq와 달리, let은 모두 동일한 시간에 변수를 바인드합니다.
(setq w 77)
;;=> 77
(let ((w 8)
(x w))
(+ w x))
;;=> 85
let은 w를 8로 x는 w로 바인드 하였습니다. 동일한 시각에 이러한 바인딩이 발생하였으므로 w는 여전히 값 77을 지니게 됩니다.
리스프는 순서대로 바인딩을 수행하는 let*이라는 let의 변종을 지녔습니다.
(setq u 37)
;;=> 37
(let* ((v 4)
(u v))
(+ u v))
;;=> 8
COND
cond 매크로는 조건적으로 리스프 폼을 평가하도록 합니다. let처럼, cond는 폼의 다양한 부분을 구분짓기 위해 괄호를 이용합니다. 이 예제를 살펴보시기 바랍니다:
(let ((a 1)
(b 2)
(c 1)
(d 1))
(cond ((eql a b) 1)
((eql a c) "First form" 2)
((eql a d) 3)))
;;=> 2
위에 정의된 cond 폼에서 3개의 절을 정의하였습니다. 각 절은 테스트 폼으로 시작하는 리스트이며 원하는 만큼의 바디(body) 폼이 뒷따라 나옵니다. 바디 폼은 테스트가 성공일시 실행되는 코드 입니다. 순차적으로 절이 선택됩니다 - 하나의 테스트가 성공하면 그에 대응하는 바디 폼이 평가되고 그 바디 폼의 마지막 값이 cond 폼의 값이 됩니다.
cond는 여러 절을 다룰 수 있기에, 스페셜 폼 if에 비해 범용적입니다.
이제 예제에서 어떤일이 수행되는지 살펴보도록 하겠습니다. 두 인자가 동일하거나, 동일한 숫자면 eql 은 T를 반환합니다(17장[p 174]에서 다루게될 미묘한 다름이 있긴 합니다). 3개의 테스트중 두개만 실행되었습니다. 첫번째 (eql a b)는 NIL을 반환합니다. 그러므로, 1을 포함하는 절은 넘어갑니다. 두번째 절은 (eql a c)를 테스트하며 이는 참입니다. 이 테스트가 NIL이 아닌 값을 반환하기에, 절의 나머지 부분이 평가가 되어, 마지막 폼의 값이 cond의 값으로 반환된 다음, 최종적으로 let의 반환값으로써 반환됩니다. 세번째 절은 이미 이전 절이 선택되었기에 평가되지 않습니다 - 절들은 순서대로 선택됩니다.
관습적으로 cond의 마지막 절의 테스트 폼으로 T를 사용합니다. 이는 다른 절들이 모두 테스트에 실패를 하면 마지막 절의 바디 폼이 평가된다는 것을 보증합니다. 기본 값을 반환하거나 기타 다른 적절한 작업을 수행하기 위해 이 마지막 절을 활용할 수 있습니다. 여기 예제가 있습니다:
(let ((a 32))
(cond ((eql a 13)
"An unlucky number")
((eql a 99)
"A lucky number")
(t
"Nothing special about this number")))
;;=> "Nothing special about this number"
QUOTE
가끔씩 리스프의 평가 규칙을 적용시키지 않고 싶을 때가 있을것입니다.. 이러한 예 중 하나를 꼽자면, 함수 호출의 인자로써 심볼의 값보다 심볼 그 자체를 쓰고 싶을 때입니다:
(setq a 97)
;;=> 97
a
;;=> 97
(setq b 23)
;;=> 23
(setq a b)
;;=> 23
a
;;=> 23
(setq a (quote b))
;;=> B
a
;;=> B
차이점은 (setq a b)에서 사용된 b의 값 과 (setq a (quote b))에서의 심볼 b입니다.
quote 폼은 매우 자주 사용되며, 리스프는 다음과 같은 표기법를 제공합니다:
(QUOTE form) == 'form
리스프는 리더 매크로를 통해 '와 quote를 동일하게 처리합니다. 레슨 12 [p 82]에서 어떻게 여러분만의 리더 매크로를 정의할 수 있는지 간략하게 살펴볼 것입니다.
짚고 넘어가기
setqletcond',quote
레슨 04. 조립과 분해
CONS
cons는 리스트의 가장 기본적인 구성 요소입니다. 이는 함수므로 이의 인자들을 평가합니다. 리스트를 만들때에는 cons의 두번째 인자로 리스트 혹은 NIL이 들어올것입니다.
(cons 1 nil)
;;=> (1)
(cons 2 (cons 1 nil))
;;=> (2 1)
(cons 3 (cons 2 (cons 1 nil)))
;;=> (3 2 1)
cons는 새로운 항목을 리스트의 시작 부분에 추가합니다. 비어있는 리스트 ( ) 는 NIL과 동일하며,
( ) == NIL
따라서 이렇게 작성할 수 있습니다:
(cons 1 ())
;;=> (1)
(cons 2 (cons 1 ()))
;;=> (2 1)
(cons 3 (cons 2 (cons 1 ())))
;;=> (3 2 1)
혼란스럽게 느껴진다면, 맞습니다, NIL에는 뭔가 특별한 능력이 있습니다. NIL은 키워드는 아니지만 자기 자신을 상수 값으로 가지는 리스프의 두개의 심볼 중 하나입니다. 또 다른 심볼은 T입니다.
( ) == NIL이란 것과 NIL이 스스로 평가된다는 것을 종합해보면, 이는 (quote ())를 ()로 쓸 수 있다는 것을 의미합니다. 그렇지 않았다면, 리스프는 빈 리스트를 처리하기 위해 평가 규칙에 예외를 추가해야 했을 것입니다.
LIST
아마 여러분이 눈치챗다면, 중첩된 cons 폼으로도 리스트가 만들어질 수 있다는 것은 조금 지루할 수 도 있습니다. list 폼은 좀더 명료한 방법으로 동일한 일을 수행합니다:
(list 1 2 3)
;;=> (1 2 3)
list는 여러 인자를 취할 수 있습니다. list는 함수이기에, 이는 인자를 평가합니다:
(list 1 2 :hello "there" 3)
;;=> (1 2 :HELLO "there" 3)
(let ((a :this)
(b :and)
(c :that))
(list a 1 b c 2))
;;=> (:THIS 1 :AND :THAT 2)
FIRST와 REST
리스트가 (첫번째와 나머지) 두 부분으로 만들어졌다고 가정한다면, 여러분은 first와 rest 두 연산자를 이용하여 리스트의 개별 원소들을 얻을 수 있습니다:
(setq my-list (quote (1 2 3 4 5)))
;;=> (1 2 3 4 5)
(first my-list)
;;=> 1
(rest my-list)
;;=> (2 3 4 5)
(first (rest my-list))
;;=> 2
(rest (rest my-list))
;;=> (3 4 5)
(first (rest (rest my-list)))
;;=> 3
(rest (rest (rest my-list)))
;;=> (4 5)
(first (rest (rest (rest my-list))))
;;=> 4
first와 rest 함수를 이리저리 엮는 것은 분명 지루한 작업일 것입니다. 또, 이러한 접근 법은 프로그램에서 특정 요소만을 선택하고자 할때나 혹은 리스트의 길이가 무한일때 잘 먹히지 않을 것입니다. 4장[p 84] 에서 재귀 함수를 정의할때 이러한 문제를 어떻게 해결하는지 살펴볼 것입니다. 나중에 13장에서 [p 150], 리스프가 제공하는 리스트 혹은 시퀀스 속 요소를 선택할 수 있는 함수들을 살펴 볼 것입니다
first와 rest는 꽤 최근 동안 활약해온 car와 cdr 함수의 이름을 바꾸어 리스프에 추가된 것입니다. 초기 리스프 구현체 중 하나에서 car와 cdr의 이름이 유례됬고, 이 이름에 기반한 구현체가 이미 오래전에 바뀌었음에도 불구하고 수십년간 고수되었습니다
짚고 넘어가기
conslistfirstrestcarcdrnil,( )T
레슨 05. 네이밍과 아이덴티티(Naming and Identity)
심볼은 단지 이름
심볼은 단지 이름입니다. 심볼은 심볼 그 자체 입니다. 이는 리스프에서 특정 종류의 프로그램을 작성하는 것을 쉽게 만들어 줍니다. 예를들어, 프로그램으로 가족 관계를 나타내고자 한다면, 이와 같은 관계를 나타내는 데이터베이스를 만들 수 있습니다:
(father John Barry)
(son John Harold)
(father John Susan)
(mother Edith Barry)
(mother Edith Susan)
...
각각의 관계를 리스트로 표현했습니다. 예로 (father John Barry)는 John은 Barry의 아버지라는 것을 의미합니다. 데이터베이스 속 리스트의 모든 요소는 심볼입니다. 예를들어 Harold는 Barry의 할아버지라는 것을 판별하기 위해 리스프 프로그램은 이 데이터베이스안에 있는 심볼들을 비교할 수 있습니다.
심볼이 없는 다른 언어 언어에서 이와 같은 프로그램을 작성하고자 한다면, 가족 구성원의 이름과 관계를 어떻게 표현해야할지 결정해야만 해야하며, 거기에 필요한 모든 동작들을 (읽고, 출력하고, 비교하고, 할당하고, 기타등등) 수행하는 코드를 작성해야만 할 것입니다. 이름을 지정하는 데 사용되는 오브젝트들과는 별개의 데이터 타입인 심볼이기에 이 모든 것들이 리스프에 이미 내장되어 있습니다.
심볼은 항상 유니크하다.
프로그램에서 이름이 같은 심볼은 항상 동일합니다. eq 테스트로 심볼을 비교할 수 있습니다:
(eq 'a 'a)
;;=> T
(eq 'david 'a)
;;=> NIL
(eq 'David 'DAVID)
;;=> T
(setq zzz 'sleeper)
;;=> SLEEPER
(eq zzz 'sleeper)
;;=> T
심볼 이름으로 대문자나 소문자를 사용하는 것은 문제가 되지 않습니다. 내부적으로, 리스프는 심볼 이름에 있는 모든 알파벳 문자들을 보통은 대문자로 바꾸며, 리스프 리더 속에 있는 플레그를 설정하여 이 기본 설정을 제어할 수 있습니다.
레슨 10 [p 65](또한 31장 [p 247]참조)에서 패키지에 대해 배운다면, 스펠은 같지만 동일하지는 않는 심볼 이름을 만들 수 있습니다. 지금 알아야 할것은 : 로 표시된 심볼은 특별하게 취급한다 라는 것입니다.
심볼로 값에 이름 붙일 수 있다.
심볼의 자기 자신을 표현하는 능력 역시 유용하지만, 더욱 일반적으로 사용되는 곳은 값의 이름을 붙일 때입니다. 이는 다른 프로그래밍 언어에서 변수와 함수 이름의 역활을 맡습니다. 리스프 심볼은 값의 이름이나, 함수의 이름을 지을 때 사용됩니다.
리스프에서 특이한 점 중 하나는 심볼은 함수랑 변수의 값을 동시에 지닐 수 있다 라는 점 입니다:
(setq first 'number-one)
;;=> NUMBER-ONE
(first (list 3 2 1))
;;=> 3
first
;;=> NUMBER-ONE
첫번째와 마지막 경우에서의 first는 변수 이며 , 두번째인 경우는 리스프에 의해 미리 정의된 함수 라는 점을 주의깊게 보시길 바랍니다. 리스프는 심볼이 보이는 곳에 기반하여 이 값이 무엇인지 결정합니다. 평가 규칙에 따라 값을 요청받으면, 리스프는 심볼의 변수 값을 찾습니다. 함수를 요청받으면, 리스프는 심볼의 함수 값을 찾습니다.
심볼은 변수나 함수의 값 외에 다른 값을 가질 수 있습니다. 심볼은 문서, 프로퍼티 리스트(property list) 혹은 출력시 표시되는 값을 가질 수 있습니다. 심볼의 문서는 해당 심볼의 설명을 위한 텍스트입니다. documentation 폼을 사용하거나 심볼의 값을 정의하는 몇몇 폼에서 심볼에 대한 문서도 같이 만들 수 있습니다. 심볼은 다양한 의미를 가질 수 있으므로 함수 및 변수와 같이 여러 가지 의미에 맞는 각각에 대한 문서를 만들 수 있습니다.
프로퍼티 리스트는 엔트리(entry)당 하나의 키를 지닌 자그마한 데이터 베이스와 같습니다. 레슨 10 [p 65]에서 이러한 심볼의 사용법을 살펴볼 것입니다.
출력 이름은 리스프에서 심볼을 출력하기 위해 사용하는 것입니다. 일반적으로 이 이름을 변경하지 않는게 좋습니다; 다른 이름으로 변경한다면, 다른 이름으로 출력된 결과를 리스프가 다시 읽어들일때 원래 심볼값과 다른 의미로 받아들여 혼란을 야기할 것입니다.
값은 하나 이상의 이름을 가질 수 있다
값은 하나 이상의 이름을 가질 수 있습니다. 즉, 하나 이상의 심볼이 동일한 값을 공유할 수 있다는 것입니다. 다른 언어에서 이러한 방식으로 동작하는 것으로는 포인터가 있습니다. 리스프는 프로그래머에게 포인터를 노출하진 않지만, 공유되어 사용되는 오브젝트들이 있습니다. eq 테스트로 오브젝트가 서로 같은지 확인할 수 있습니다. 다음에 나오는 것을 살펴보시기 바랍니다:
(setq L1 (list 'a 'b 'c))
;;=> (A B C)
(setq L2 L1)
;;=> (A B C)
(eq L1 L2)
;;=> T
(setq L3 (list 'a 'b 'c))
;;=> (A B C)
(eq L3 L1)
;;=> NIL
여기서, 동일한 값을 L1과 L2라 이름지엇기에, L1과 L2는 eq합니다. 다시 말하자면 (list 'a 'b 'c) 폼에 의해 생성된 값은 L1과 L2라는 두개의 이름을 갖습니다. (setq L2 L1) 폼은 "L2의 값이 L1의 값이 되도록 해라" 라고 지시합니다. 값의 복사를 말 하는게 아니라, 값 그 자체를 지칭합니다. 따라서 L1과 L2는 동일한 값 (처음 L1에 할당된 리스트 (A B C))을 공유합니다.
또한 L3도 리스트 (A B C)를 값으로 갖지만, 이는 L1과 L2가 공유하는 것과는 다른 새로운 리스트 입니다. 비록 L3의 값이 L1과 L2의 값과 동일한 것처럼 보이지만, 다른 list 폼에 의해 생성되었기에, 이는 다른 리스트입니다. 따라서, 서로 심볼 A, B, C로 구성된 리스트이지만, 다른 리스트이기에 (eq L3 L1)는 NIL이 됩니다.
짚고 넘어가기
eq
레슨 06. 바인딩(binding) vs 할당(Assignment)
바인딩은 값을 담을 새로운 공간을 만든다
리스프는 종종, 변수의 값을 담기 위해 새로이 메모리를 할당하여 바인딩을 만듭니다. 바인딩은 변수의 렉시컬 스코프(lexical scope) 구현을 위한 매우 일반적인 매커니즘이지만, 바인딩의 라이프타임에 따라 다른 용도로도 사용됩니다. 8장[p 126]에서 라이프타임(lifetime)과 가시성(visibility)를 공부할때 이를 다시 논할 것입니다.
리스프는 새로운 바인딩을 위해 저장공간을 할당합니다. 이것이 끔찍하게 비효율적인 것처럼 보이지만, 아직 리스프가 어디에 저장공간을 할당하는지에 대해서는 알 수 가 없습니다. 예를들어, 리스프는 함수 인자를 값으로 바인드할때, 다른 프로그래밍 언어들처럼 스택(stack)에 저장공간을 할당합니다. 리스프는 바인딩의 라이프타임을 판단할 수 없으면 해당 바인딩을 힙(heap)에 생성합니다.
바인딩은 이름을 가진다
리스프는 각 바인딩마다 이름을 부여합니다. 만일 그렇지 않다면, 프로그램은 어떻게 바인딩을 참조할 수 있을까요? 간단하게, 어? 잠시만요...
바인딩은 동시에 다른 값을 가질 수 있다
중첩 바인딩에서 동일한 이름을 공유하는 것은 매우 일반적인 일입니다. 예를들어:
(let ((a 1))
(let ((a 2))
(let ((a 3))
...)))
여기서, (...으로 표시된) 가장 안쪽의 let에 도착할 쯤에는, a는 3개의 서로 다른 바인딩을 가지게 됩니다.
단, 위 예제가 전형적인 리스프 코드라고 말하는 것은 결코 아닙니다.
가장 가까운 바인딩
;; 여기서는, A는 바인딩 되지 않습니다.
(let ((a 1))
;; 여기서 A의 가장 가까운 바인딩은 값 1을 갖습니다.
(let ((a 2))
;; 여기서 A의 가장 가까운 바인딩은 값 2을 갖습니다.
(let ((a 3))
;; 여기서 A의 가장 가까운 바인딩은 값 3을 갖습니다.
...)))
보시다시피, 가장 가까운 바인딩이란 상대적인 위치를 가집니다. 바인딩 폼이 어떻게 중첩되었는지 살펴보면 (위에서 보인것처럼 여러분의 코드를 들여쓰기하였다면 이를 하기에 쉬울 것입니다), 어떻게 프로그램이 바인딩에 접근하는지 알 수 있습니다.
한가지 더 여러분이 알아야 할것은, 내부 바인딩 폼이 동일한 심볼을 바인드하지 않는 한, 내부 바인딩 폼에서도 외부 바인딩이 여전히 유효하다는 점 입니다:
;; 여기서, A와 B는 바인딩 되지 않습니다.
(let ((a 1)
(b 9))
;; 여기서, A의 가장 가까운 바인딩은 값 1을 지니며,
;; B의 바인딩은 값 9를 지닙니다.
(let ((a 2))
;; 여기서, A의 가장 가까운 바인딩은 값 2를 지닙니다.
;; B의 바인딩은 여전히 값 9를 지닙니다.
(let ((a 3))
;; 여기서, A의 가장 가까운 바인딩은 값 2를 지닙니다.
;; B는 여전히 외부의 LET 폼에서의 값 9를 지닙니다.
...)))
이미 만든 바인딩에만 프로그램이 접근할 수 있습니다.
바인딩 폼이 새로운 값을 이미 존재하는 심볼에 바인딩하면, 이전의 값은 가려지게 됩니다. 프로그램이 내부 바인딩 폼을 실행하는 동안에, 외부 바인딩 값이 감춰집니다 (단, 사라지지는 않습니다). 그러나, 프로그램이 내부 바인딩 폼을 빠저나가면, 외부 바인딩 값이 복구됩니다. 예를들어:
(let ((z 1))
;; 여기서, Z의 가장 가까운 바인딩은 값 1을 지닙니다.
(let ((z 2))
;; 여기서, Z의 가장 가까운 바인딩은 값 2을 지닙니다.
...)
;; 이제 여러분은 내부 바인딩 폼을 빠져나왔으며,
;; 다시 바인딩 값 1을 보게됩니다.
...)
할당은 오래된 장소에 새로운 값을 줍니다. gives an old place a new value
setq 폼은 이미 존재하는 바인딩 값을 바꿉니다:
(let ((z 1))
;; 여기서, Z의 가장 가까운 바인딩은 값 1을 지닙니다.
(setq z 9)
;; 이제 값 Z는 9입니다.
(let ((z 2))
;; 여기서, Z의 가장 가까운 바인딩은 값 2을 지닙니다.
...)
;; 이제 여러분은 내부 바인딩 폼을 빠져나왔으며,
;; 다시 Z의 외부 바인딩 값 9을 보게됩니다.
...)
위의 setq 폼은, 바깥쪽 let 폼에서 정의된 z의 바인딩값을 바꿉니다. 이는 종종 좋지 않은 일을 불러옵니다. 문제라고 생각되는 점은 z의 값을 확인하기 위해 살펴봐야만 하는 곳이 이제 두 곳으로 늘어났다는 것입니다 - 첫번째는 바인딩 폼, 그 다음은 setq로 할당한 코드. 들여쓰기를 활용하는 바인딩 폼과는 달리, 프로그램의 본체 부분에서 할당하는 폼에는 따로 들여쓰기가 없습니다; 프로그램을 읽을때 이러한 부분을 찾아내는것이 어렵습니다.
이전 예제에서 봤던것과 같이 새로운 바인딩을 도입하여 매우 쉽게 할당하는 코드를 우회할 수 있습니다.
(let ((z 1))
;; 여기서, Z의 가장 가까운 바인딩은 값 1을 지닙니다.
(let ((z 9))
;; Z의 새 값은 이제 9.
(let ((z 2))
;; 여기서, Z의 가장 가까운 바인딩은 값 2을 지닙니다.
...)
;; 이제 여러분은 내부 바인딩 폼을 빠져나왔으며,
;; 다시 중간에 있는 바인딩 값 9가 Z의 바인딩 값이 됩니다.
...)
;; 여기서, 가장 바깥쪽 바인딩 값 1이 Z의 바인딩 값이 됩니다.
...)
이제 let폼의 들여쓰기로 인해 z의 모든 바인딩을 알아보기 쉬워졌습니다. 프로그램의 어느 지점에서(예제에서는 ...에서) z의 올바른 바인딩을 찾기 위해 여러분이 해야할 일은 프로그램을 읽을 시 들여쓰기를 주의하여 상위 레벨에 있는 let 폼을 찾아보는 것입니다.
let 폼으로 둘러싸여 있지 않는 곳에서 setq 폼이 어떠한 변수를 할당하고 있다면, 이는 전역 변수이거나 특수(special) 변수일 것입니다.
전역 변수는 다른 바인딩으로 가려지지 않는한 어느곳에서나 접근이 가능하며, 리스프 시스템이 동작하는 동안 사용할 수 있습니다. 특수(special) 변수는 8장[p 126]에서 살펴볼 것입니다.
(setq a 987)
;; 여기서, A는 전역 값 987를 지녔습니다.
(let ((a 1))
;; 여기서, A의 바인딩 값 1이 전역 변수의 값을 가리게 됩니다.
...)
;; 이제 A의 전역 값이 다시 살아났습니다.
...
짚고 넘어가기
- 바인딩(binding)
레슨 07. 필수 - 함수 정의(Essential Function Definition)
DEFUN - 이름을 가진 함수 정의
defun 폼을 이용하여 이름을 가진 함수를 정의할 수 있습니다:
(defun secret-number (the-number)
(let ((the-secret 37))
(cond ((= the-number the-secret) 'that-is-the-secret-number)
((< the-number the-secret) 'too-low)
((> the-number the-secret) 'too-high))))
;;=> SECRET-NUMBER
레슨 3에서 let, cond, '(quote의 별칭)를 다루었습니다. 숫자 비교 함수들은 그 의미가 명확합니다.
defun 폼은 3개의 인자를 가집니다:
- 함수의 이름:
secret-number - 인자 이름 리스트: 이것이 호출되엇을시 함수의 인자가 될
(the-number) - 함수의 본체:
(let ...)
3개 모두 각각 그 그대로 나타내어야 하므로, defun은 인자를 평가하지 않습니다 (만일 평가가 수행되었다면, 각 인자에 quote를 붙여야만 하는 불편함이 생길 것입니다).
defun은 정의된 함수 이름을 반환하고, 여러분이 제공한 이름, 인자 리스트, 본체를 이용하여 함수의 정의를 전역으로 선언합니다. defun을 이용하여 함수를 만들고 나면 바로 이를 사용할 수 있습니다:
(secret-number 11)
;;=> TOO-LOW
(secret-number 99)
;;=> TOO-HIGH
(secret-number 37)
;;=> THAT-IS-THE-SECRET-NUMBER
함수를 호출할때, 이것의 인수는(예. 두번쩨 예제에서 99) 정의에서 사용한 인자 이름(즉. the-umber)에 바인딩이 됩니다. 그런 다음, 함수의 본체 (즉. (LET ...))은 해당 인자의 바인딩 컨텍스트로 평가됩니다. 다른 말로 하자면, (SECRET-NUMBER 99)를 평가하는 것은 99가 변수 THE-NUMBER로 바인딩 된체 SECRET-NUMBER 함수 본체를 실행하도록 만들어 줍니다.
물론, 여러분은 하나 이상의 인자를 지닌 함수를 정의 할 수 있습니다.
(defun my-calculation (a b c x)
(+ (* a (* x x))
(* b x)
c))
;;=> MY-CALCULATION
(my-calculation 3 2 7 5)
;;=> 92
함수를 호출할때 인수들은 순서에 맞게 인자 이름에 바인딩 됩니다. 리스프는 인자 이름의 리스트는 여러가지 변형들이 있습니다. 공식적으로 이러한 변형 리스트를 람다 리스트라 부릅니다 - 21장[p 198]에서 이것의 다른 기능들에 대해 살펴 볼 것입니다.
LAMBDA - 이름 없는 함수 정의
때로는 프로그램에서 단 한곳에서만 쓰이는 함수가 필요할 것입니다. defun으로 함수를 만들어 이를 한번만 호출할 수 있습니다. 그리고 때때로 프로그램을 읽을 때를 도움이 되도록 함수에 잘 짜여진 이름을 부여할 수 도 있습니다. 그러나 종종 여러분이 필요한 함수는 아주 사소하거나 아주 명백하여 이름을 굳이 지을 필요가 없거나, 이전에 같은 이름이 쓰였는지에 대해 걱정하지 않고 싶을 때가 있을 것입니다. 이와 같은 상황에서, 리스프에선 lambda 폼을 이용하여 이름 없는 함수를 만들 수 있습니다. lambda 폼은 마치 이름이 없는 defun 폼처럼 보입니다:
(lambda (a b c x)
(+ (* a (* x x))
(* b x)
c))
여기서 lambda 폼을 평가할 수 없습니다; 이는 리스프가 함수 자리라고 예상되어 지는 곳에서만 보여야 합니다 - 보통 폼의 첫번째 요소;
(lambda (a b c x)
(+ (* a (* x x))
(* b x)
c))
;;>| Error
((lambda (a b c x)
(+ (* a (* x x))
(* b x)
c))
3 2 7 5)
;;=> 92
짚고 넘어가기
defunlambda
레슨 08. 필수 - 매크로 정의(Essential Macro Definition)
DEFMACRO - 이름있는 매크로 정의
defmacro 폼은 defun 폼과 많이 유사합니다 - 이름(name), 인자 리스트(argument list), 그리고 본체(body)를 지닙니다:
(defmacro name (argument ...)
body)
매크로는 값이 아닌 폼을 반환한다
매크로 본체는 평가될 폼을 반환합니다. 다른 말로 하자면, 매크로의 본체로 값이 아닌 폼을 반환하도록 작성해야 합니다. 리스프가 매크로의 호출을 평가할때, 이는 우선 매크로 본체 정의를 평가하고, 첫번째 평가의 결과를 평가합니다 (이에 비해, 함수의 본체는 값을 반환하기 위해 평가됩니다).
다음으로 저희가 알아야 할 대부분의 내용을 설명하는 몇 가지 간단한 매크로들이 있습니다:
(defmacro setq-literal (place literal)
`(setq ,place ',literal))
;;=> SETQ-LITERAL
(setq-literal a b)
;;=> B
a
;;=> B
(defmacro reverse-cons (rest first)
`(cons ,first ,rest))
;;=> REVERSE-CONS
(reverse-cons nil A)
;;=> (B)
setq-literal는 인수가 평가되지 않는다는 점을 제외하면 마치 setq처럼 동작합니다(SETQ는 이의 두번째 인수를 평가한다는 것을 명심하시기 바랍니다). SETQ-LITERAL의 본체는 ("역따옴표"라 불리는) `로 시작하는 폼을 지녔습니다. 따옴표처럼 역따옴표로 묶인 모든 폼의 평가를 억제하지만, 역따옴표 안에서 쉼표가 나타나는 경우는 예외입니다. 쉼표 뒤에 오는 심볼은 평가됩니다.
따라서 위의 (SETQ-LITERAL A B)를 호출함에 있어, 무슨 일이 벌어지는지 여기 나와 있습니다:
- 심볼
A를PLACE에 바인드한다. - 심볼
B를LITERAL에 바인드한다. - 다음 단계를 거처
`(SETQ ,PLACE ',LITERAL)본체를 평가한다:PLACE를 평가하여 심볼A를 얻는다.LITERAL를 평가하여 심볼B를 얻는다.- 폼
(SETQ A 'B)를 반환한다.
- 폼
(SETQ A 'B)를 평가한다.
반환된 폼에서 역따옴표나 쉼표는 보이지 않습니다. SETQ-LITERAL 호출에서 A나 B가 평가되지 않지만 서로 다른 이유 때문입니다. A는 SETQ의 첫번째 인수이기에 평가되지 않습니다. B는 매크로에 의해 반환된 폼앞에 따옴표(')가 보이기에 평가되지 않습니다
(REVERSE-CONS NIL A)의 동작은 유사합니다:
- 심볼
NIL을REST에 바인드한다. - 심볼
A를FIRST에 바인드한다. - 다음 단계를 거처,
`(CONS ,FIRST ,REST)본체를 평가한다:FIRST를 평가하여 심볼A를 얻는다.REST를 평가하여 심볼NIL를 얻는다.- 폼
(CONS A NIL)를 반환한다.
- 폼
(CONS A NIL)을 평가한다.
CONS는 이의 인수들을 평가하며, 매크로 본체에서 두 인자에 따옴표를 붙이지 않았기에, reverse-cons의 두 인수는 평가됩니다. A는 심볼 B로 평가되며, NIL은 자기자신으로 평가됩니다.
여러분이 평가되기전에 매크로 본체가 어떤지 확인하고자 한다면, macroexpand 함수를 이용할 수 있습니다:
(macroexpand '(setq-literal a b))
;;=> (SETQ A 'B)
(macroexpand '(reverse-cons nil a))
;;=> (CONS A NIL)
macroexpand는 함수이기에 인자를 평가합니다. 때문에 확장시키고자 하는 폼 앞에 따옴표가 있어야 합니다.
일부러 이번 레슨의 예제를 매우 간단한 걸로 놓았으므로, 여러분은 매우 간단 기본 매커니즘을 이해할 수 있을 것입니다. 일반적으로, 매크로는 함수보다 작성하기 힘듭니다 - 20장[p 188]에서 그 이유와 그러한 복잡한 상황을 다룰 수 있는 적절한 기법에 대해 살펴보도록 하겠습니다.
짚고 넘어가기
defmacromacroexpandmacroexpand-1
레슨 09. 필수 - 다중 값(Essential Multiple Values)
대다수의 폼은 하나의 값만 만든다
폼은 보통 하나의 값을 반환합니다. 리스프는 여러개의 값을 생성하거나 받을 수 있는 폼을 갖고 있습니다.
VALUES는 여러개의 값을 생성하거나 아무것도 생성하지 않는다
values 폼은 0개 이상의 값을 반환합니다:
(values)
;;=>
(values :this)
;;=> :THIS
(values :this :that)
;;=> :THIS
;;=> :THAT
폼의 평가에 의해 생성된 여러 라인이으로 얼마나 많은 값이 반환되었는지 보았습니다. 위의 예제에서 3개의 values 폼에서 각각 0개, 1개, 2개의 값을 생성하였습니다.
values는 함수이며, 따라서 이의 인수를 평가합니다.
몇몇 특수한 폼은 여러개의 값을 받을 수 있다
여러개의 값들을 다루고자 한다면 어떻게 해야 할까요? 가장 기본적인 것들로는 :
- 각 값들을 개별 심볼로 바인드한다.
- 혹은, 값들을 하나의 리스트로 모은다.
각 값들을 개별 심볼로 바인드하기 위해 multiple-value-bind를 이용합니다:
(multiple-value-bind (a b c) (values 2 3 5)
(+ a b c))
;;=> 10
심볼의 갯수보다 더 많은 값을 넘기면, 초과된 값은 무시됩니다:
(multiple-value-bind (a b c) (values 2 3 5 'x 'y)
(+ a b c))
;;=> 10
심볼의 갯수보다 더 적은 값을 넘기면, 나머지 심볼들은 NIL로 바인드됩니다:
(multiple-value-bind (w x y z) (values :left :right)
(list w x y z))
;;=> (:LEFT :RIGHT NIL NIL)
몇몇 폼은 여러개의 값들을 그대로 넘긴다
몇몇 폼은 새로운 값을 생성하는 대신에, 본체의 마지막 값을 넘김니다. 예제는 let, cond, defun, lambda의 본체를 포함합니다.
(let ((a 1)
(b 2))
(values a b))
;;=> 1
;;=> 2
(cond (nil 97)
(t (values 3 4)))
;;=> 3
;;=> 4
(defun foo (p q)
(values (list :p p) (list :q q)))
;;=> FOO
(foo 5 6)
;;=> (:P 5)
;;=> (:Q 6)
((lambda (r s) (values r s)) 7 8)
;;=> 7
;;=> 8
함수와 lambda 본체의 경우엔, "암시적 PROGN"라 불리는 무언가로부터 다중 값이 반환되었습니다. 본체는 다수의 폼을 포함할 수 있으며, 최종적으로 마지막 폼의 값이 반환됩니다.
progn 스페실 폼을 이용하여 위와 같은 행동을 할 수 도 있습니다. (PROGN form1 form2 ... formN) 은 순서대로 form1부터 formN까지 평가하고, 최종적으로 formN의 값을 반환합니다.
짚고 넘어가기
valuesmultiple-value-bindprogn
레슨 10. 프리뷰 - 다른 데이터 타입(A Preview of Other Data Type)
리스프는 대부분의 숫자를 제대로 처리한다
뭔가 이상한 소리처럼 들립니다. 컴퓨터는 항상 숫자로 일을 처리하지 않나요? 음, 아닙니다... 보통은 그렇지 않습니다.
수의 계산은 수 많은 방식으로 나뉠 수 있습니다. 가장 큰 문제가 되는 점 중 하나는 소수점(floating point) 계산이 있습니다 (혹여 여러분이 쓰고 있는 프로그래밍 언어가 이를 실수(real)라 부른다면, 아마 거짓말일 것입니다). 비쥬얼 어쩌고저쩌고 혹은 객체 지향 블라블라와 같은 많은 책들 중 대다수가 이 소수점 계산을 다루고 있습니다.
소수점에서의 문제는 수학적으로 실수(real)가 아니지만, 종종 실수(real)인양 (잘못) 사용된다는 점입니다. 중대한 문제는 소수를 그렇게 사용한다면, 정확도에 한계가 생긴다는 점 입니다 - 소수점 우측 몇개의 자릿수 만큼. 이제, 계산에 사용되는 모든 숫자가 거의 같은 규모의 수라면, 계산의 정확도가 떨어지지 않을 수 있을 것입니다. 그러나, 규모가 매우 차이나는 숫자들이라면, 소수점 계산은 정확도가 희생될 것입니다.
여러분의 컴퓨터의 소수가 정확하게 소숫점 7자리를 표현할수 있다고 가정해 봅시다. 그러면, 여러분은 1897482.0에 2973225.0를 더하면 완벽히 정확한 답을 얻을 수 있을 것입니다. 그러나, 1897482.0에 0.2973225를 더하고자 한다면, 정확한 답은 14자리의 숫자이지만, 여러분의 컴퓨터는 1897482.0을 답으로 할 것입니다.
소수에 관한 또 다른 문제는 더욱 미묘합니다. 프로그램을 작성할때 보통 10진수에 기반하여 수를 사용할 것입니다. 그러나 컴퓨터는 모든 연산을 2진수에 기반하여 수행합니다. 10진수에서 2진수로의 변환은 어떤 "명백히 정확한" 특정 숫자에 대해 재미난 일을 수행합니다. 예를들어, 소수 0.1은 2진수로 변환하면 순환 분수가 됩니다. 컴퓨터는 순환분수가 요구하는 무한한 숫자를 저장하지 못하기에, 0.1의 값을 정확히 저장할 수 없습니다.
또, 정수(자연수) 연산에 관한 문제를 대부분의 컴퓨터 언어들이 가지고 있습니다 - 하나의 정수를 담을 수 있는 양수나 음수의 최대치에 제한이 있는 경향이 있습니다. 따라서, 숫자 하나를 여러분의 언어에 대해 컴퓨터를 다룰 수 있는 가장 큰 정수에 더하고자 한다면, 둘 중 하나가 일어납니다:
- 에러가 발생해 프로그램이 종료된다.
- 혹은, 굉장히 부정확한 답을 얻는다. (가장 큰 양수에 1을 더한게 가장 작은 음수를 만들어 낸다던가.)
그렇다면 리스프는 숫자를 어떻게 올바르게 처리할까요? 우선, 이 문제가 컴퓨터의 연산에서 비롯된 것처럼 보입니다. 그렇다면 답은 컴퓨터 내장 산술 연산을 리스프는 직접 사용하지 않는 것입니다 - 수학적으로 정확한 특정 수치 데이터 형식을 추가하였습니다:
bignum은 무한한 정수이다 (컴퓨터 메모리의 한계에 달려있습니다)- 유리수는 두 정수의 정확한 몫이며, 나눗셈 알고리즘에서 나온 대략적인 소수가 아니다.
물론, 리스프 또한 머신 기반 정수와 소수를 지닙니다. 머신에서의 정수를 리스프에서 fixnum라 부릅니다. fixnum의 범위에서 자연수를 넘겨받으면, 리스프는 이를 머신의 정수로 저장할 것입니다. 그러나, 이게 너무 커지면, 리스프는 자동으로 이를 bignum으로 승격시킬 것입니다.
앞서 리스프는 대부분의 숫자를 제대로 처리한다고 말했는데, 거의 항상 수학적으로 옳은 수의 표현을 고른다 라는 의미로 말했었습니다:
(/ 1 3)
;;=> 1/3
(+ (/ 7 11) (/ 13 31))
;;=> 360/341
(defun factorial (n)
(cond ((= n 0) 1)
(t (* n (factorial (- n 1))))))
;;=> FACTORIAL
(factorial 100)
;;=> 933262154439441526816992388562667004907159682643816214685
;; 929638952175999932299156089414639761565182862536979208272
;; 23758251185210916864000000000000000000000000
소수점를 활용한 계산을 작성할 수 도 있지만, 리스프는 정확한 수치 결과를 자동으로 부정확한 소수로 전환할 수 없기에 일단 소수점을 활용하면, 전체 계산 결과가 소수점 유지하게 될 것입니다 (소수점 연산은 전염됩니다) :
(float (/ 1 3))
;;=> 0.3333333333333333
(* (float (/ 1 10))
(float (/ 1 10)))
;;=> 0.010000000000000002
(+ 1/100 (* (float (/ 1 10))
(float (/ 1 10))))
;;=> 0.020000000000000004
(+ 1/100 1/100) ; 이전 계산과 비교해 보시기 바랍니다
;;=> 1/50
(* 3 7 10.0)
;;=> 210.0
(- 1.0 1)
;;=> 0.0
(+ 1/3 2/3 0.0)
;;=> 1.0
(+ 1/3 2/3)
;;=> 1 ; 이전 계산과 비교해 보시기 바랍니다
리스프는 소수를 소수점과 함께, 정수에는 소수점 없이 출력합니다.
문자는 리스프가 읽고 쓸 수 있는 무언가를 제공한다
기본적으로 리스프 I/O(input/output)는 문자를 이용합니다. READ와 WRITE 함수는 문자를 리스프 오브젝트로 그리고 그 반대로 변환시킵니다. READ-CHAR와 WRITE-CHAR는 단일 문자를 읽고 씁니다.
(read)
;;<< a ⏎
;;=> A
(read)
;;<< #\a ⏎
;;=> a
(read-char)
;;<< a
;;=> #\a
(write 'a)
;;>> A
;;=> A
(write #\a)
;;>> #\a
;;=> #\a
(write-char #\a)
;;>> a
;;=> #\a
(write-char 'a)
;;>| Error: Not a character
위 예에서 새로운 표기를 추가했습니다. ;;<< 표시는 READ와 같은 입력함수에 대한 입력을 기다린다는 것을 의미합니다. ⏎은 엔터(enter)키에 의해 생성되는 개행문자를 나타냅니다.
값을 반환하는 것(;;=>)과 달리 ;;>>는 출력을 나타냅니다.
개행 시 read의 입력받는 동작이 종료된다는 것을 알아채셨을 것입니다. READ는 문자들을 모아 완벽한 리스프 표현식을 구성하고자 하기 때문입니다. 레슨 11에서 이것에 대해 좀 더 살펴볼 것입니다. 이번 예제에서, READ는 개행으로 종료되는 심볼을 모읍니다. 이 심볼은 또한 공백, 괄호, 혹은 심볼이 될 수 없는 문자일때 종료됩니다.
대조적으로, READ-CHAR는 입력에서 정확히 하나의 문자만 읽습니다. 문자를 받자마자 READ-CHAR는 실행을 완료하고 해당 문자를 반환합니다.
몇몇 리스프 시스템은 어떠한 입력을 받아들이기 전에 리턴(return) 키를 누르도록 요구받을 것입니다. 이는 일반적인게 아니며, 환경 설정 변수로 변경 할 수 있을 것입니다 - 여러분이 사용하는 리스프의 제조사와 상담을 하시기 바랍니다.
WRITE와 WRITE-CHAR는 둘 다 받은 값을 반환합니다. 값을 출력하는 방식은 다릅니다. WRITE는 값을 출력하므로, 동일한 값을 생성하는 READ로 표현할 수 있습니다. WRITE-CHAR는 단순히 읽을 수 있는 문자를 출력하며, 이는 READ에서의 문자라는 것을 나타내는 추가 리스프 문법 (#\)을 포함하지 않습니다.
리스프는 단일 문자를 #\char 표기법을 이용하여 표시하는데, 이러한 char에 들어가는 것으로는 리터럴(literal) 문자이거나 상형문자로 출력 할 수 없는 문자의 이름이 있습니다.
| 문자 | 16진수 | Lisp | 표준? |
|---|---|---|---|
| space | 20 | #\Space | yes |
| newline | -- | #\Newline | yes |
| backspace | 08 | #\Backspace | semi |
| tab | 09 | #\Tab | semi |
| linefeed | 0A | #\Linefeed | semi |
| formfeed | 0C | #\Page | semi |
| carriage return | 0D | #\Return | semi |
| rubout or DEL | 7F | #\Rubout | semi |
#\Space와 #\Newline만이 모든 리스프 시스템에서의 요구사항 입니다. ASCII 문자셋를 이용하는 시스템은 아마 위에 나온 나머지 문자코드를 구현했을 것입니다.
\#Newline 문자는 호스트 시스템에 맞게 출력 라인의 끝을 표시하는 컨벤션(convention)을 따를것입니다. 예로:
| 시스템 | 개행 | 16진수 |
|---|---|---|
| Macintosh | CR | 0D |
| MS-DOS | CR LF | 0D 0A |
| Unix | LF | 0A |
94개의 출력 가능한 표준 문자들이 \#char로 표현됩니다:
! " # $ % & ' ( ) * + , - . /
0 1 2 3 4 5 6 7 8 9 : ; < = > ?
@ A B C D E F G H I J K L M N O
P Q R S T U V W X Y Z [ \ ] ^ _
‘ a b c d e f g h i j k l m n o
p q r s t u v w x y z { | } ~
배열은 데이터를 테이블로 정리한다
여러분이 데이터를 2차원, 3차원 혹은 더 많은 차원의 테이블로 역으려고자 한다면, 배열(array)을 만들 수 있습니다:
(setq a1 (make-array '(3 4)))
;;=> #2A((NIL NIL NIL NIL)
;; (NIL NIL NIL NIL)
;; (NIL NIL NIL NIL))
(setf (aref a1 0 0) (list 'element 0 0))
;;=> (ELEMENT 0 0)
(setf (aref a1 1 0) (list 'element 1 0))
;;=> (ELEMENT 1 0)
(setf (aref a1 2 0) (list 'element 2 0))
;;=> (ELEMENT 2 0)
a1
;;=> #2A(((ELEMENT 0 0) NIL NIL NIL)
;; ((ELEMENT 1 0) NIL NIL NIL)
;; ((ELEMENT 2 0) NIL NIL NIL))
(aref a1 0 0)
;;=> (ELEMENT 0 0)
(setf (aref a1 0 1) pi)
;;=> 3.141592653589793
(setf (aref a1 0 2) "hello")
;;=> "hello"
(aref a1 0 2)
;;=> "hello"
MAKE-ARRAY를 사용하여 배열의 차원에 나타내는 리스트를 넘겨 배열을 만들었습니다. 기본적으로, 배열은 어떠한 종류의 데이터라도 담을 수 있습니다; 성능을 위해 데이터 타입을 추가 인자로 넣어 제한 할 수도 있습니다.
배열의 랭크(rank)는 차원(dimension)과 동일합니다. 위 예제에서 저희는 2차원 배열을 만들었습니다. 리스프는 #rankA(...)표기법을 이용하여 배열을 출력합니다. 배열의 내용물은, 첫번째 차원이 최상단 그룹의 요소로 보여지고, 마지막 차원이 최하단 그룹의 요소로 보여지는, 중첩된 리스트 표시됩니다.
여러분의 리스프 시스템은 아마도 여기서 보여졌던것 처럼 라인을 넘기면서 배열을 출력하지 않을 수 도 있습니다. 여기서는 배열의 구조를 강조하기 위해 라인을 넘기면서 표시하였습니다.
AREF를 이용하여 배열의 요소를 얻습니다. AREF의 첫번째 인수는 배열입니다; 나머지 인수로 각 차원의 인덱스(index)를 지정합니다. 인덱스는 배열의 랭크와 맞아야만 합니다.
배열의 요소를 설정하기 위해선, 이 예제에서 보인것 처럼 SETF 폼 내부에서 AREF를 사용합니다. SETF는 SETQ와 유사하지만, SETQ는 심볼에게 값을 할당하고, SETF는 위치에 값을 할당합니다. 예제에서 AREF 폼은 배열의 요소로 위치를 지정했습니다.
백터는 일차원 배열
백터(Vector)는 일차원 배열입니다. MAKE-ARRAY를 이용하여 벡터를 만들 수 있으며, AREF를 이용해 요소에 접근 할 수 있습니다.
(setq v1 (make-array '(3)))
;;=> #(NIL NIL NIL)
(make-array 3)
;;=> #(NIL NIL NIL)
(setf (aref v1 0) :zero)
;;=> :ZERO
(setf (aref v1 1) :one)
;;=> :ONE
(aref v1 0)
;;=> :ZERO
v1
;;=> #(:ZERO :ONE NIL)
리스프는 #1A(...)이 아닌 조금 간소화된 #(...) 폼을 이용하여 벡터를 출력합니다.
단일 원소 리스트나 벡터의 차원을 지정한 MAKE-ARRAY 중 선택할 수 있습니다.
VECTOR 폼에 값들을 나열하여 벡터를 만들 수 있습니다:
(vector 34 22 30)
;;=> #(34 22 30)
결과값이 리스트가 아닌 벡터라는 점을 제외하면, 이는 LIST 폼과 유사합니다. 리스트와 벡터 사이에는 닮은게 하나 더 있습니다: 둘 다 시퀀스(sequence)입니다. 13장[p 150]에서 만나게 될 함수들로 시퀀스를 조작할 수 있습니다.
벡터의 요소에 접근하기 위해 AREF를 사용하거나, 시퀀스에 특화된 함수 ELT를 사용할 수 있습니다:
(setf v2 (vector 34 22 30 99 66 77))
;;=> #(34 22 30 99 66 77)
(setf (elt v2 3) :radio)
;;=> :RADIO
v2
;;=> #(34 22 30 :RADIO 66 77)
문자열은 문자를 담고있는 백터
여러분은 이미 "..."를 이용하여 문자열(string)을 작성하는 법을 알고 있습니다. 문자열은 벡터이기에, 문자열의 요소에 접근하기 위해 배열과 백터의 함수들을 적용할 수 있습니다. 또한 make-string 함수를 이용하여 문자열을 만들거나, string 함수를 이용하여 문자나 심볼을 문자열로 바꿀 수 있습니다.
(setq s1 "hello, there.")
;;=> "hello, there."
(setf (elt s1 0) #\H))
;;=> #\H
(setf (elt s1 12) #\!)
;;=> #\!
s1
;;=> "Hello, there!"
(string 'a-symbol)
;;=> "A-SYMBOL"
(string #\G)
;;=> "G"
심볼은 유니크하지만, 여러개의 값을 가진다
이미 레슨 5에서 심볼은 고유한 동일성(identity)을 지닌다고 했는데, 반복해 설명할 필요가 있습니다: 심볼은 철자가 같은 다른 심볼과 동일합니다(이번 레슨 끝부분에서 좀 더 배우게 될 패키지 지정(designation)에 포함된). 이는 리스프로 하여금 프로그램이나 데이터를 읽을 수 있도록 만들어 주며, 철자가 같은 심볼은 모두 동일한 심볼입니다. 리스프가 이를 위한 매커니즘을 제공하기에, 심볼 정보를 다루는 프로그램을 작성하는 것에 대한 걱정을 하나 덜게 되었습니다.
저희는 또한 레슨 5에서 심볼은 변수와 함수, 그리고 문서, 출력 이름, 프로퍼티(properties)를 위한 값을 가질 수 있다고 배웠습니다. 심볼의 프로퍼티 리스트(property list)는 다수의 키/값 쌍이 심볼과 연결된 아주 작은 데이터베이스와 같습니다. 예를들어, 여러분의 프로그램이 오브젝트를 표현하고 다루고자 한다면, 오브젝트에 관한 정보를 프로퍼티 리스트에 저장할 수 있습니다:
(setf (get 'object-1 'color) 'red)
;;=> RED
(setf (get 'object-1 'size) 'large)
;;=> LARGE
(setf (get 'object-1 'shape) 'round)
;;=> ROUND
(setf (get 'object-1 'position) '(on table))
;;=> (ON TABLE)
(setf (get 'object-1 'weight) 15)
;;=> 15
(symbol-plist 'object-1)
;;=> (WEIGHT 15 POSITION (ON TABLE) SHAPE ROUND SIZE LARGE COLOR RED)
(get 'object-1 'color)
;;=> RED
object-1
;;>| Error: no value
OBJECT-1은 값을 갖지 않는다는 점을 주목하시기 바랍니다 - 중요한 것은 바로 이 두 부분입니다: 심볼의 동일성과 심볼의 프로퍼티.
이러한 프로퍼티의 이용은 현대의 객체 지향 프로그래밍보다 몇 십년이나 앞서 나왔습니다. 이는 오브젝트의 필수적인 3가지 매커니즘 중 2가지를 제공합니다: 동일성(identify)과 캡슐화(encapsulation) (프로퍼퍼티의 값 역시 함수가 될 수 있다는 점을 명심하시기 바랍니다). 3번째 매커니즘 상속(inheritance)은 다른 "오브젝트"를 연결하여 시뮬레이션합니다.
오늘날의 리스프 프로그램에서는 프로퍼티는 거의 사용되지 않습니다. 해쉬테이블(Hashtables) (아래 참조) [p 73] , (다음 단락에서 기술된) 구조체(structures), CLOS 오브젝트(7장 [p 117]과 14장 [p 157] 참조)는 사용하기 더 편리하며 더욱 효율적인 방식으로 프로퍼티 리스트의 모든 기능을 제공합니다. 현대 리스프의 개발에선 프로퍼티 파일과 심볼을 정의하는 폼의 파일 위치, 함수의 인자 리스트의 정의와 같은 (프로그래밍 환경에서 유용한 도구로 이용하기 위한) 특정 정보를 프로그램에 주석으로써 기록하는 목적으로 주로 사용합니다.
구조체는 연관된 데이터들을 모아 저장할 수 있다
리스프 구조체는 명명된 슬롯(slot)과 관계된 데이터를 저장하는 오브젝트를 생성하는 방법을 제공해 줍니다.
(defstruct struct-1
color
size
shape
position
weight)
;;=> STRUCT-1
(setq object-2 (make-struct-1
:size 'small
:color 'green
:weight 10
:shape 'square))
;;=> #S(STRUCT-1 :COLOR GREEN
;; :SIZE SMALL
;; :SHAPE SQUARE
;; :POSITION NIL
;; :WEIGHT 10)
(struct-1-shape object-2)
;;=> SQUARE
(struct-1-position object-2)
;;=> NIL
(setf (struct-1-position object-2) '(under table))
;;=> (UNDER TABLE)
(struct-1-position object-2)
;;=> (UNDER-TABLE)
이 예에서, 우리는 COLOR, SHAPE, SIZE, WEIGHT 슬롯을 지닌 STRUCT-1 구조체를 정의하였습니다. 그런 다음 STRUCT-1의 인스턴스(instance)를 만들고, 해당 인스턴스를 변수 OBJECT-2에 할당하였습니다. 예제의 나머지 부분은, 구조체의 타입과 슬롯 이름으로 구성된 접근자(assessor)함수를 이용하여, 어떻게 구조체 인스턴스의 슬롯에 접근할 수 있는지 보여주고 있습니다. DEFSTRUCT를 이용하여 구조체를 정의하면 리스프는 make-구조체명과 구조체명-슬롯명 함수도 만들어 줍니다.
6장[p 112]에서 DEFSTRUCT의 optional 기능에 대해 살펴볼 것입니다.
타입 정보를 런타임에 알 수 있다
심볼은 런타임시 어떠한 변수 타입과도 연관지을 수 있습니다. 문제가 있는 경우, 리스프는 해당 값의 타입을 질의할 수 있는 방법을 제공합니다:
(type-of 123)
;;=> FIXNUM
(type-of 123456789000)
;;=> BIGNUM
(type-of "hello, world")
;;=> (SIMPLE-BASE-STRING 12)
(type-of 'fubar)
;;=> SYMBOL
(type-of '(a b c))
;;=> CONS
TYPE-OF 는 인수의 타입을 나타내는 심볼 혹은 리스트를 반환합니다. 게다가 이 정보를 이용하여 인자의 타입에 기반한 프로그램의 동작 방식을 조정 할 수 있습니다. TYPECASE 함수는 타입에 대한 질의(inquiry)와 COND-와 같은 분기(dispatch)를 결합한 것입니다.
CLOS(14장 [p 157] 참조)의 제네릭 함수의 도입으로, TYPE-OF는 예전만큼 중요하지는 않습니다.
해쉬 테이블은 룩업키로 빠르게 데이터에 접근 할 수 있다
해쉬 테이블은 유니크 키(유일 키, unique key)와 값의 연결로 이루어져 있습니다. 프로퍼티 리스트완 다르게, 해쉬 테이블은 수 많은 키/값 쌍에 적합하며, 적은 수의 연결 집합에 대해서는 과도한 오버헤드(overhead)가 발생합니다.
(setq ht1 (make-hash-table))
;;=> #<HASH-TABLE>
(gethash 'quux ht1)
;;=> NIL
;;=> NIL
(setf (gethash 'baz ht1) 'baz-value)
;;=> BAZ-VALUE
(gethash 'baz ht1)
;;=> BAZ-VALUE
;;=> T
(setf (gethash 'gronk ht1) nil)
;;=> NIL
(gethash 'gronk ht1)
;;=> NIL
;;=> T
MAKE-HASH-TABLE을 이용하여 해쉬 테이블을 만들었으며, GETHASH를 이용하여 값에 접근하였습니다. GETHASH는 두개의 값을 반환합니다. 첫번째는 해당 키와 연결된 값입니다. 두번째는 키를 찾으면 T, 아니면 NIL입니다. 위 예제에서 GETHASH폼의 처음과 마지막 차이를 주목하시기 바랍니다.
해쉬테이블은 기본적으로 EQ(이는 숫자나 리스트가 아닌 심볼에 대해서만 동작합니다)를 이용하여 키를 비교하도록 만들어졌습니다. 17장[p 174]에서 동등성 판단(equality predicates)에 대해 더 자세히 배울 것입니다. 지금은 키에 숫자를 사용하려면 다음과 같은 형식을 사용하여 해시 테이블을 만들어야 한다는 점만 명심하시기 바랍니다:
(make-hash-table :test #'eql)
리스트를 키로 사용하고자 한다면, 이렇게 해쉬테이블을 만듭니다:
(make-hash-table :test #'equal)
키를 없애고자 한다면 (REMHASH key hash-table)폼을 이용합니다. 그리고 키에 해당하는 값을 바꾸고자한다면, 키/값 쌍을 추가했던 것처럼 GETHASH와 SETF를 이용합니다.
패키지로 이름 충돌을 방지할 수 있다
프로그램을 작성시 어려운 점 중 하나는 이름 짓는 것입니다. 한편으론, 기억하기 쉽고 해당 객체의 역할이나 목적을 떠올릴 수 있는 이름을 사용하기 원할 것입니다. 그리고 다른 한편으론, 다른 프로그램의 어딘가에 이미 사용한 (혹은 사용될 것 같은)이름을 여러분의 프로그램에서 사용하고 싶진 않을 것입니다.
이름 충돌(naming conflict)을 피하는 법 중 하나는 프로그램에 있는 모든 이름에 누구도 사용하지 않는 고유 접두사(prefix)를 붙이는 것입니다. 라이브러리에서 이러한 방식을 자주 볼 수 있습니다 - 보통 1~3자로 접두사를 붙입니다. 불행히도, 여전히 두 소프트웨어 개발자가 동일한 접두사를 선택할 수 있는 관문이 남아있습니다; 일부 접두사가 다른 접두사들보다 더 매력적인 경우. 모든 소프트웨어를 제어할 수 있다면, 모든 접두사를 선택하여 문제를 피할 수 있습니다. 타사 소프트웨어를 구입하는 경우, 제조사에 의해 선택된 이름을 사용해야만 하며, 동일한 접두사를 사용하지 않기를 바래야만 할 것입니다.
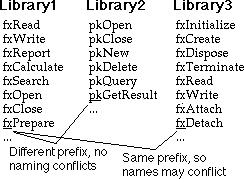
이름 충돌을 피하는 또 하나의 방법은 한정된 이름(qualified name)을 사용하는 것입니다. 이를 위해, 언어는 프로그래머에 의해 정의되고 제어되는 분리된 이름공간을 제공해야 합니다. 어떻게 이것이 동작하는지 이해하기 위해, 프로그램에 쓰이는 모든 이름이 한장에 종이 상단의 타이틀 부분에 작성되었다고 상상해보시기 바랍니다. 이름을 사용해도 안전한지 확인하려면, 이 페이지에 작성한 이름 목록을 확인하기만 하면 됩니다. 누군가의 소프트웨어가 여러분의 프로그램의 서비스를 필요로 할 때, 그 누군가는 여러분들이 한정한 이름을 참조할 것입니다. 다른이의 소프트웨어는 그들만의 규칙이 이름을 한정할 것이며 있을 것이며, 이름 충돌이 발생할 가능성이 없습니다.
한정자는 이름에 접두사를 추가하는 복잡한 방법에 지나지 않는다고 생각할 수 있습니다. 그러나, 거기엔 미묘하며 중대한 차이점이 있습니다. 접두사는 이름의 일부이므로 한 번 쓰면 변경할 수 없습니다. 한정자는 한정하는 이름과 분리되어 있으며 정확히 한 곳에 "기록"되었습니다. 더욱이, 이름이 적혀 있는 "종이"를 가리키며 "이러한 이름들"이라고 지칭할 수 있습니다. 다른 프로그래머와 동일한 한정자를 선택한 경우에도, 자신이 선택한 한정자로 "그 이름들"을 지칭할 수 있습니다 - 다른 말로 하자면, 여러분이 사용할 소프트웨어가 출고된 후에도, 한정자를 변경할 수 있습니다.

위 예로 두 라이브러리 LIB1와 LIB2가 있습니다. 두 라이브러리를 설계한 사람은 리스프에서 패키지 이름으로 알려진 이름 공간(namespace)을 UTIL이라 이름 붙였습니다. 각 라이브러리는 클라이언트에 노출될 이름들이 나열되어 있습니다. 두 라이브러리를 이용하는 프로그래머는 MY-PACKAGE란 패키지 이름에서 코드를 작성했습니다. 각 라이브러리를 로드한 후, 이름들을 구분할 수 있도록 프로그래머는 이의 패키지 이름을 바꾸었습니다. 그러면, UTIL-1:INITIALIZE와 UTIL-2:INITIALIZE의 호출에서 봤던 것처럼, 라이브러리에 있는 이름들은 이름이 바뀐 한정자를 활용하여 참조됩니다. 프로그래머는 한정자가 없는 INITIALIZE란 이름을 여전히 사용 할 수 있다는 점을 주목하시기 바랍니다 - 이는 MY-PACKAGE:INITIALIZE와 동일합니다.
;;;; file: util1.lisp
(defpackage util1
(:export init func1 func2)
(:use common-lisp))
(in-package util1)
(defun init () 'util1-init)
(defun func1 () 'util1-func1)
(defun func2 () 'util1-func2)
;;;; file: util2.lisp
(defpackage util2
(:export init func1 func2)
(:use common-lisp))
(in-package util2)
(defun init () 'util2-init)
(defun func1 () 'util2-func1)
(defun func2 () 'util2-func2)
;;;; file: client.lisp
(defpackage client
(:use common-lisp)
(:import-from util1 func1)
(:import-from util2 func2))
(in-package client)
(defun init () 'client-init)
(util1:init)
(util2:init)
(init)
(func1)
(func2)
예제는 세개의 파일의 내용물을 나열했습니다. util1.lisp와 util2.lisp는 모두 동일한 이름으로 3개의 함수를 정의하였습니다. util1.lisp는 이름들을 UTIL1패키지에 넣었으며, util2.lisp는 UTIL2패키지를 이용합니다. defpackage 폼은 패키지의 이름을 정의합니다. :use 옵션은 한정자 없이 이름을 가져올 패키지명을 지정하며, :EXPORT 옵션은 패키지에서 다른 클라이언트들에게 노출될 이름들을 지정합니다.
defpackage 폼은 단지 패키지를 생성합니다. use-package 폼은 패키지를 현재 사용 중인 패키지로 만듭니다 - 한정하지 않은 모든 이름들은 현재 패키지에 포함됩니다. COMMON-LISP:*PACKAGE* 변수는 항상 현재 이용중인 패키지를 포함합니다.
client.lisp은 CLIENT 패키지를 만듭니다. :INFORT-FROM 옵션은 UTIL1과 UTIL2패키지로부터 특정 이름들을 가져옵니다 - 여기서 가져온 이름들은 CLIENT패키지에서 한정자 없이 사용할 수 있습니다. UTIL1나 UTIL2에서 익스포트(export)하고, CLIENT에서 임포트(import)가 되지 않은 이름들은, pakcage:name 폼과 같이 명시적 한정자(explicit qualifier)를 이용하여 CLIENT에서 참조하여 사용할 수 있습니다.
이번 단락에선 아주 기초적인 패키지 연산만을 다루었습니다. 31장[p 247]에서, 더 큰 규모의 소프트웨어 시스템을 구축하면서 패키지의 좀 더 자세한 내용을 다룰 것입니다.
짚고 넘어가기
readwriteread-charwrite-charmake-arrayarefvectoreltstringtype-ofmake-hash-tablegethashremhashdefstructdefpackagein-package
레슨 11. 필수 - 입력과 출력(Essential Input and Output)
READ는 리스프 데이터를 받는다
레슨 10에서 봤던것처럼, read는 문자를 리스프 데이터로 변환시킵니다. 이제까지, 우리들은 리스프 데이터 여러 출력 값들을 살펴 보았습니다:
- 심볼과 숫자
- 문자, 문자열, 리스트, 배열, 백터, 구조체
- 해쉬태이블
리스프 리더(reader)는 문자 분류법(classifications)를 따라 이와 같은 일을 수행합니다. 표준 분류법은 아래에 나와있습니다. 레슨 12에서 보게될 것처럼, 여러분은 필요에 따라 이러한 분류법을 바꿀 수도 있습니다.
표준 구성 문자(Standard Constituent Characters)
-------------------------------
a b c d e f g h i j k l m n o p q r s t u v w x y z
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
0 1 2 3 4 5 6 7 8 9
! $ % & * + - . / : < = > ? @ [ ] ^ _ { } ~
<backspace> <rubout>
표준 종료 매크로 문자(Standard Terminating Macro Characters)
-------------------------------------
" ' ( ) , ; ‘
표준 비-종료 매크로 문자(Standard Non-Terminating Macro Characters)
-----------------------------------------
#
표준 단일 이스케이프 문자(Standard Single Escape Characters)
---------------------------------
\
표준 다수 이스케이프 문자(Standard Multiple Escape Characters)
-----------------------------------
|
표준 공백 문자(Standard Whitespace Characters)
------------------------------
<tab> <space> <page> <newline> <return> <linefeed>
READ가 구성문자(constituent character)로 시작된다면, 이는 심볼이나 숫자를 축적하기 시작합니다. READ가 종료 매크로 문자(terminating macro character)나 공백 문자(whitespace character)를 만나면, 이는 모아진 구성문자를 우선 숫자로, 그 다음 심볼로 해석하기 시작합니다. 숫자로 해석이 가능하다면 READ는 숫자를 반환합니다. 그렇지 않으면, READ는 영문자를 표준문자(standard case (보통은 대문자))로 바꾸어, 심볼로써 이름을 인턴(intern)하여 심볼을 반환합니다.
이스케이프 문자(Escape characters)는 특별한 역활을 수행합니다. 하나의 이스케이프 문자는 다음에 나오는 문자를 마치 구성문자(constituent character)처럼 다루도록 합니다. 보통 공백이나 종료 매크로 문자로 취급되는 문자는 심볼의 일부가 될 수 있습니다. 이스케이프된 것이 숫자일 지라도, READ가 이스케이프 문자를 만나면 결과를 숫자로 해석하려 하지 않을 것입니다
READ시 매크로 문자(macro character)로 시작한다면, 아래의 문자들이 다음 단계를 결정하게 됩니다:
| 문자 | 설명 |
|---|---|
| " | 문자열을 읽는다. |
| ' | 폼을 읽는다. |
| ( | 리스트를 읽는다. |
| ; | 새로운 라인을 만나기 전까지 모든 것을 무시한다. |
| # | 다음 나오는 문자에 기반하여 무엇인지 결정한다. |
마지막으로, 몇몇 리스프 데이터는 읽을 수 없습니다. 예를들어, 해쉬테이블의 출력결과는 #<HASH-TABLE>와 같습니다. #< 문자로 시작하는 어떠한 것을 읽으려할때 READ는 에러를 뱉을 것입니다.
PRINT는 여러분을 그리고 READ를 위한 리스프 데이터를 작성한다.
print 함수는 리스프 오브젝트를 문자 시퀀스(sequence of characters)로 바꿉니다. 이 문자 시퀀스는 READ에서 재구성하는 데 필요로 하는 것입니다:
(print 'abc)
;;>> ⏎
;;>> ABC⌴
;;=> ABC
(print (list 1 2 3))
;;>> ⏎
;;>> (1 2 3)⌴
;;=> (1 2 3)
(print "A String")
;;>> ⏎
;;>> "A string"⌴
;;=> "A string"
(print 387.9532)
;;>> ⏎
;;>> 387.9532⌴
;;=> 387.9532
(print (make-hash-table))
;;>> ⏎
;;>> #<HASH-TABLE>⌴
;;=> #<HASH-TABLE>
PRINT는 개행(⏎)으로 시작하고 띄어쓰기(⌴)으로 끝나는 결과물을 출력합니다. 이는 PRINT 출력이 다른 출력들과 구별되도록 만들어 줍니다. 개행과 띄어쓰기 모두 공백(whitespace)으로 취급되며, 이는 (이스케이프되지 않는 한) 리스프 오브젝트를 출력하는데 하는데 포함될 수 없습니다.
PRINT와 비슷한 다양한 쓰임세를 지닌 다른 변종들이 있습니다. PRIN1은 PRINT와 비슷하게 행동하지만, 공백으론 감싸지 않습니다. 예를들어 여러 조각들로 이름을 만들고자 할때 유용하게 쓰일 것입니다. PRINC는 PRIN1처럼 행동하지만 READ를 위하기 보단, 유저에게 보여지는것을 위한 결과물을 생성합니다; 예를들어, PRINC는 문자열을 둘러싸는 쌍따옴표를 생략하며, 이스케이프 문자 역시 출력하지 않습니다.
(print 'a\ bc)
;;>> ⏎
;;>> |A BC|⌴
;;=> |A BC|
(prin1 'a\ bc)
;;>> |A BC|
;;=> |A BC|
(princ '|A BC|)
;;>> ⏎
;;>> A BC⌴
;;=> |A BC|
OPEN과 CLOSE는 파일을 다룰 수 있게 한다
보통, READ는 키보드를 읽고 PRINT는 화면에 출력합니다. 이러한 함수 모두 옵셔널(optional) 인수를 취합니다; 인수로 READ를 위한 입력 스트림과 PRINT를 위한 출력 스트림을 지정합니다. 스트림(stream)은 무엇일까요? 스트림은 데이터의 소스(source)이자 밑바닥(sink)이며, 보통은 (그치만 절대적이지는 않은) 문자들(characters)입니다. 이제부터, 저희는 텍스트 파일이 어떻게 문자 스트림의 소스가 될 수 있는지를 살펴볼 것입니다. 19장 [p 183]에서 저희는 몇몇 다른 가능성들을 살펴볼 것입니다.
파일 이름을 인수로 취하고 스트림의 방향(입력과 출력)을 결정하는 키워드 인수를 취하는, OPEN 함수를 이용하여 스트림을 파일로 연결 시킬 수 있습니다. 스트림에 대한 작업을 끝내고 연결된 파일을 닫기 위해선 CLOSE 함수를 사용합니다.
(setq out-stream (open "my-temp-file" :direction :output))
;;=> #<OUTPUT-STREAM "my-temp-file">
(print 'abc out-stream)
;;=> ABC
(close out-stream)
;;=> T
(setq in-stream (open "my-temp-file" :direction :input))
;;=> #<INPUT-STREAM "my-temp-file">
(read in-stream)
;;=> ABC
(close in-stream)
;;=> T
이 예제에서, 저희는 my-temp-file에 대한 출력 스트림을 만들었으며, 심볼 ABC를 그 스트림에 출력하였습니다. 여느때와 같이 인자를 반환하지만, 출력은 하지않았다는 점을 주목해주시길 바랍니다 - 출력된 결과는 파일로 갔습니다.
다음으로, 출력 스트림을 닫고 동일한 파일로 입력 스트림을 열었습니다. 그런 다음 저희가 파일에 출력한 심볼을 읽어온 다음, 입력 스트림을 닫음으로써 끝을 맺었습니다.
PRINT의 여러가지 변종 태마
리스프는 또한 이러한 옵션을 제어하는 키워드 인자를 사용하여, 출력을 더욱 세부적으로 제어할 수 있는 WRITE라는 함수를 제공합니다:
| 키워드 인자 | 기본 값 | 행동 |
|---|---|---|
| :stream | t | 출력 스트림 설정 |
| :escape | *print-escape* | 이스케이프 문자 포함 |
| :radix | *print-radix* | 진법(radix (base)) 프리픽스 |
| :base | *print-base* | 숫자가 몇 진법을 사용할지 설정 |
| :circle | *print-circle* | 순환(circular) 구조물 출력 |
| :pretty | *print-pretty* | 가독성을 위한 공백 추가 |
| :level | *print-level* | 중첩 단계 한계 |
| :length | *print-length* | 중첩 단계당 아이템의 한계 |
| :case | *print-case* | :upper, :lower, 혹은 :mixed |
| :gensym | *print-gensym* | uninterned 심볼의 접두사 |
| :array | *print-array* | 가독성 있게 배열 출력 |
| :readably | *print-readably* | 강제로 가독성있게 |
| :right-margin | *print-right-margin* | 가독성있게 출력하는 옵션 |
| :miser-width | *print-miser-width* | '' |
| :lines | *print-lines* | '' |
| :pprint-dispatch | *print-pprint-dispatch* | '' |
우연하게도, 위에 키워드 인자의 기본값으로 나온 변수들은 또한 PRINT의 연산을 제어합니다. 여러분은, 키워드 인자를 쓰지 않고 LET 폼에서 이러한 변수에 바인딩 하고 PRIN1를 감싸면 WRITE과 동일한 효과를 얻을 수 있습니다:
(write foo
:pretty t
:right-margin 60
:case :downcase)
(let ((*print-pretty* t)
(*print-right-margin* 60)
(*print-case* :downcase))
(prin1 foo))
print가 아닌 prin1를 사용했는데, PRINT는 앞에 개행(⏎) 있고 뒤에 빈칸(⌴)이 오기 때문입니다.
*PRINT-...*류의 변수를 바꿨다가, 프로그램의 어느 지점에서 다시 기본 값(default value)을 쓰고자 한다면, with-standard-io-syntax 폼으로 감쌀 수 있습니다:
;; 프로그램의 출력 제어를 정의한다.
(setq *print-circle* t)
(setq *print-array* nil)
(setq *print-escape* nil)
...
;; 위에서 설정한 걸 출력한다.
(print ...)
...
;; 원래의 출력 제어 설정으로 되돌린다.
(with-standard-io-syntax
...
;; 기본 설정으로 출력한다음,
;; 위에서 설정한 것들을 덮어버린다.
(print ...)
...)
;; WITH-STANDARD-IO-SYNTAX 폼 밖에선,
;; 예제 상단에 있는 SETQ 폼에 의해 설정된
;; print의 설정을 또 다시 해야한다.
짚고 넘어가기
printprin1princwritewith-standard-io-syntaxopenclose*print-circle**print-array**print-escape*
레슨 12. 필수 - 리더 매크로(Essential Reader Macros)
리더(reader)는 문자를 데이터로 만든다
레슨 11에서 리스프 리더(reader)가 구성문자들을 심볼과 숫자로 모았으며, 매크로 문자들로 리더를 제어하여 리스트, 문자열, quote된 폼, 주석을 처리하는 것을 보았습니다. 이 모든 경우에서와 같이, 리더(reader)는 문자들을 데이터로 바꿉니다 (좀 더 정확히 하자면, 주석은 "데이터가 아닙니다".)
표준 리더 매크로는 내장 데이터 타입을 다룰 수 있다
지금까지, 우리는 리스프의 기본 문법만을 살펴보았습니다. 이는 리더에 의해 구현되며, 리드테이블(readtable)에 의해 제어됩니다. 리더는 리드테이블에 저장되어있는 정보를 따라 문자들을 처리합니다.
사용자는 리더 매크로를 정의할 수 있다
*readtable*변수를 통해 리드테이블(readtable)에 접근할 수 있으며, 리드테이블에 있는 항목을 조작할 수 있는 함수들을 리스프는 제공합니다. 여러분은 이를 이용하여 리스프 리더의 행동을 바꿀 수 있습니다. 다음 예제에선, 문법을 바꾸어 [와 ]를 이용하여 평가되지 않는 리스트를 작성하였습니다:
;;이는 틀렸습니다:
(1 2 3 4 5 6)
;;>| Error: 1 is not a function
;; 대신에 이렇게 해야 합니다:
'(1 2 3 4 5 6)
;;=> (1 2 3 4 5 6)
;;새로운 문법을 정의하여
;; '(1 2 3 4 5 6) ; 대신에
;; [1 2 3 4 5 6] ; 이처럼 작성할 수 있게 합시다.
(defun open-bracket-macro-character (stream char)
`',(read-delimited-list #\] stream t))
;;=> OPEN-BRACKET-MACRO-CHARACTER
(set-macro-character #\[ #'open-bracket-macro-character)
;;=> T
(set-macro-character #\] (get-macro-character #\)))
;;=> T
;;이제 테스트 해봅시다:
[1 2 3 4 5 6]
;;=> (1 2 3 4 5 6)
처음 저희는 (1 2 3 4 5 6)을 평가해보려 시도했습니다: 1은 함수가 아니기에, 이는 옳지 않습니다. 이제 저희가 해야만하는 것은 리스트를 quote 하는 것입니다. 그러나 이러한 작업을 매번 해야한다면, 더욱 편리한 문법을 원하게 될 것입니다. 좀 더 구체적으로, [...]이 '(...) 처럼 동작했으면 좋겠습니다.
이를 수행하기 위해, 인수를 평가하지 않는 특수 리스트 리더 매크로 함수를 정의해야 합니다. 리더가 [ 문자를 만나면 함수가 호출되도록 할 것입니다; 함수는 ] 문자를 만나면 리스트를 반환할 것입니다. 모든 리더 매크로 함수는 두 인수에 의해 호출됩니다: 입력 스트림과 매크로를 작동시키는 문자.
리스프에는 리스트를 읽을 수 있도록 설계된 함수가 있어, 쉽게 리드 매크로를 만들 수 있었습니다. READ-DELIMITED-LIST는 하나의 인수를 기다립니다 - 현재 읽고 있는 리스트를 종료시키는 문자. 다른 두개의 인자는 선택 사항입니다 - 입력 스트림과 플래그 (리더 매크로 함수에서 사용될땐 보통 T로 설정되는). READ-DELIMITED-LIST는 종료 문자를 마주치기 전까지 입력 스트림에서 오브젝트를 읽은 후, 모든 오브젝트를 리스트로 반환합니다. 이것만으로도 평가를 억제하는 것(suppressing)을 제외한 저희가 필요한 모든것을 수행 할 수 있습니다.
레슨 3에서 봤던 것 처럼, QUOTE (혹은 ')는 평가를 막습니다. 그러나 여기서 '(READ-DELIMITED-LIST ...)를 사용할 수 없습니다; 이는, 저희가 평가하고자 하는 폼의 평가도 막아버립니다... 대신, quote된 폼에 대해 선택적으로 평가를 할 수 있는 `(레슨 8 참조)를 사용하였습니다.
저희 OPEN-BRACKET-MACRO-CHARACTER의 정의에서 내부의 폼을 평가하지만 결과는 quote된 결과를 반환하기 위해
`',form
을 사용하였습니다.
- 리스프는 프로그래머를 위해 6개의 문자를 예약하였습니다:
[ ] { } ! ?
여러분은 이중 일부나 전체를 매크로 문자를 정의할 수 있습니다. 그러나, 다른 프로그래머와 코드를 공유할때, 논란이 될 수 있다라는 점을 주의하셔야 합니다.
짚고 넘어가기
*readtable*